
Da ereignisgesteuerte Microservices zu einer der beliebtesten Architekturen für den Aufbau verteilter, datenkonsistenter Systeme in großem Maßstab werden, sehen sich viele Unternehmen mit der ultimativen Gleichung von Systemeffizienz und Kosten konfrontiert. Eine Herausforderung, der wir uns bei Trax ebenfalls gestellt haben, ist es, jederzeit für einen großen Datenzufluss bereit zu sein und gleichzeitig die Rechenkosten so niedrig wie möglich zu halten. In diesem Blog werden wir unsere spezielle Lösung vorstellen, die einige der grundlegenden APIs aller Cloud-Anbieter nutzt. Dieser innovative Ansatz hat uns geholfen, die Verzögerungen im System zu minimieren und ~65 % der Rechenkosten einzusparen.
Diese hochmoderne Innovation wurde von AWS in einer Folge von This is My Architecture vorgestellt.
Bei Trax digitalisieren wir die physische Welt des Einzelhandels mithilfe von Computer Vision. Die Umwandlung einzelner Regalbilder in Daten und Erkenntnisse über die Bedingungen in Einzelhandelsgeschäften wird durch die "Trax Factory" ermöglicht. Die Trax Factory basiert auf einer asynchronen, ereignisgesteuerten Architektur und ist ein Cluster von Microservices, bei dem die Ausführung eines Dienstes die Aktivierung eines anderen Dienstes auslöst.
Die Trax Computer Vision Factory Architektur
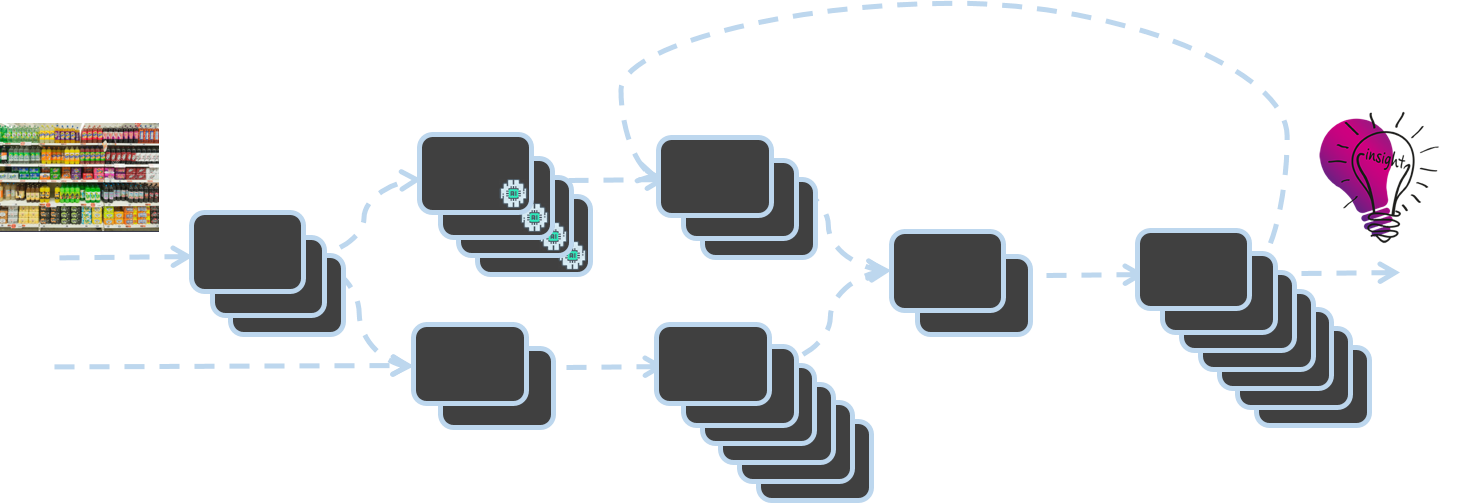
Dieser Blog erörtert die Notwendigkeit einer robusten, skalierbaren Infrastruktur zur Unterstützung der Trax Factory und stellt innovative Lösungen vor, die von Trax-Ingenieuren entwickelt wurden, um Kapazitäten je nach Bedarf hinzuzufügen oder zu entfernen. Erfahren Sie, wie Trax ein auf EC2 Auto Scaling Groups basierendes Nachrichtenverarbeitungssystem für SNS/SQS entwickelt hat, das jede Sekunde skalieren kann. Unsere Lösung geht über das klassische 5-Minuten-Scannen der Warteschlangentiefe mit CloudWatch hinaus und ermöglicht es uns, Ausfallzeiten zu reduzieren, Datenverluste zu vermeiden und die Servicequalität insgesamt zu verbessern.
Die Notwendigkeit der Skalierung
Anfang der 90er Jahre veröffentlichte Electronic Arts ein Rennspiel namens Need for Speed, bei dem die Spieler verschiedene Arten von Rennen absolvieren mussten, während sie bei Verfolgungsjagden der Polizei ausweichen mussten.
Zu dieser Zeit wurden auch die von verschiedenen Unternehmen genutzten Computer immer weiter verbreitet, und Wissenschaftler und Technologen suchten nach Möglichkeiten, die Rechenleistung in großem Maßstab durch Time-Sharing einer größeren Zahl von Benutzern zur Verfügung zu stellen. So begann die Ära des Cloud Computing und mit ihr die ständige Herausforderung der Infrastrukturoptimierung. In diesem Spiel mit dem "Need for Scale" fügen Infrastrukturteams Systemkapazitäten hinzu und entfernen sie wieder, während sie sich an die von COOs, CFOs und CTOs aufgestellten Gesetze halten. Die Ingenieure von Trax mussten, wie ihre Kollegen in anderen Cloud-basierten Technologieunternehmen, die Skalierung optimieren und gleichzeitig den Kundenservice verbessern, die Kosten senken und die Einfachheit des IT-Systems bewahren.
Die Herausforderung der Skalierung bei Trax
Trax verfügt über die branchenweit fortschrittlichste Computer Vision-Plattform für den Einzelhandel mit einem hochentwickelten Backend-System, das jeden Monat Millionen von Regalbildern verarbeitet.
Ein neues Bild, das in das System gelangt, ist eines der wichtigsten Ereignisse, die vom Trax-Backend verarbeitet werden. Dieses Ereignis löst einen Mikrodienst aus, der die Produkte auf dem Bild mithilfe fortschrittlicher Deep-Learning-Algorithmen erkennt. Dieser Prozess ist insofern asynchron, als dass kein anderer Mikrodienst auf eine Antwort von diesem Bilderkennungsdienst wartet. Seine Aufgabe endet mit der Veröffentlichung eines Ereignisses, sobald er die Verarbeitungsaktivität abgeschlossen und die Ergebnisse geliefert hat. Verschiedene Mikrodienste in der Trax Factory arbeiten auf diese Weise und führen ständig zahlreiche Aktivitäten wie Stitching, Geometrie und vieles mehr aus, die jeweils einen unterschiedlichen Grad an Rechenkomplexität erfordern.
Die Umwandlung von Millionen von Bildern aus verschiedenen Projekten rund um den Globus in gezielte, spezifische Erkenntnisse für Kunden erfordert viel Rechenleistung und belastet das IT-Budget.
In der Regel werden Entscheidungen über eine Kapazitätserweiterung oder -verringerung (Hinzufügen bzw. Verringern von Maschinen) auf der Grundlage grundlegender Metriken zur Warteschlangentiefe getroffen, die von Cloud-Anbietern bereitgestellt werden - z. B. wie viele Nachrichten sich in der Warteschlange befinden.
Für diese Skalierungspolitik gibt es zwei wesentliche Hindernisse:
- Die Aufwärmzeit eines neuen Geräts beträgt ca. 3 Minuten.
- Cloud-Anbieter melden die Anzahl der Nachrichten in der Warteschlange einmal alle 5 Minuten
In einem komplexen System wie Trax, in dem Bilder in unterschiedlichen Mengen in die Fabrik gelangen und die Auslastung der einzelnen Dienste unterschiedlich ist, werden die Informationen zur Warteschlangentiefe in 5-Minuten-Intervallen veraltet. Dies birgt nicht nur die Gefahr, dass die benötigte Rechenleistung sehr spät erkannt wird und SLAs gefährdet sind, sondern auch, dass zusätzliche Kosten bei der Anpassung der Skalierung entstehen.
Veranschaulichung von Scaling Monitor unter Verwendung von Out-of-the-Box-Kapazitätsmetriken
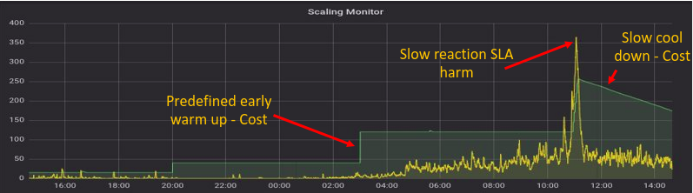
- Das gelbe Diagramm zeigt die erwartete Anzahl der benötigten Maschinen unter Berücksichtigung der Gesamtzahl der Meldungen in der Warteschlange und der Meldungen in Bearbeitung
- Das grüne Diagramm zeigt die tatsächliche Anzahl der Maschinen auf der Cloud-Plattform
Wie aus dem Diagramm hervorgeht, führt das Verlassen auf fertige Metriken zur Überwachung der Kapazitätsauslastung alle 5 Minuten dazu, dass Kosten für Maschinen anfallen, die nicht genutzt werden, und dass die Servicequalität durch den Betrieb unzureichender Maschinen beeinträchtigt wird (z. B. zwischen 10.00 und 12.00 Uhr im Diagramm).
Über die Tiefe der Warteschlange als Maßstab hinausgehen
Die Warteschlangentiefe war und wird auch in Zukunft ein wichtiger Einflussfaktor bei Skalierungsentscheidungen in ereignisbasierten Systemen sein. Wenn man sich jedoch ausschließlich auf die Warteschlangentiefe als Skalierungsmaßstab verlässt, entsteht ein reaktiver Ansatz zur Optimierung der Infrastruktur.
Wenn eine Nachricht in einer Warteschlange wartet, nimmt sie wertvolle Rechenzeit in Anspruch, die wir lieber für eine Nachricht verwenden würden, die gerade von einem Dienst verarbeitet wird. Daher ist es ideal, wenn zu einem bestimmten Zeitpunkt eine gewisse Menge an freier Rechenleistung zur Verfügung steht. Diese Reservesysteme warten darauf, dass neue Nachrichten in der Warteschlange eintreffen, damit sie sofort und ohne Verzögerung verarbeitet werden können. Dieser proaktive Ansatz ist natürlich besser als das Hinzufügen von Rechnern, wenn bereits Nachrichten in der Warteschlange sind, und das Skalieren, wenn die Warteschlange bereits leer ist. Der Bedarf an Reserveleistung offenbart eine wichtige Erkenntnis: Die Tiefe der Warteschlange sagt nicht alles aus.
Die richtige Gleichung für die Skalierung müsste also lauten:
Bedarf = Meldungen in der Warteschlange + Meldungen in Bearbeitung + freie Maschinen
Die Gründe für häufigere Kapazitäts- und Belastungsmessungen
Wie wir in den vorangegangenen Abschnitten festgestellt haben, ist es nicht nur kostspielig, sich nur einmal in 5 Minuten auf Skalierungsmetriken zu verlassen, sondern beeinträchtigt auch das Serviceniveau und die Kundenzufriedenheit. Um dieses Problem zu lösen, haben wir einen Dienst entwickelt, der die Warteschlangentiefe und die in Bearbeitung befindlichen Nachrichten jede Sekunde über die API misst. Vergleicht man die alte Stichprobenmethode mit der neuen, so sind die Verbesserungen sehr deutlich. In der folgenden Abbildung übersteigt die Nachfrage (gelbe Linie) nie das Angebot (grüne Linie).
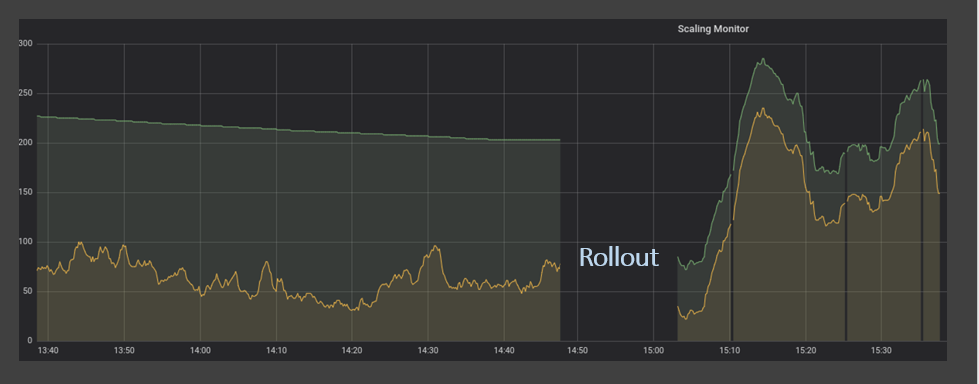
Wenn die Nachfrage stark ansteigt, reagiert das Angebot sehr schnell und schützt so unsere Kunden vor unangenehmen Verzögerungen im Service.
Darüber hinaus trägt diese Methode dazu bei, dass sich unsere überschüssige Computerleistung eng an den Bedarf anpasst, anstatt sie für ungenutzte Instanzen zu verwenden, die auf neue Nachrichten warten.
Vorsichtiges Ein- und Aussteigen
Eine aggressive Skalierung, die nicht korrekt durchgeführt wird, birgt eine eindeutige und gegenwärtige Gefahr: die Möglichkeit der Skalierung in Maschinen, die noch Informationen verarbeiten. In der Trax-Fabrik zum Beispiel benötigen geometriebasierte Algorithmen im Vergleich zu anderen Diensten in der Regel mehr Verarbeitungszeit. Wird diesem Dienst zu früh Rechenleistung entzogen, führt dies dazu, dass die Nachricht wieder in die Warteschlange gestellt wird. Infolgedessen werden in den Bedarfsberichten nicht nur die natürlichen Zuflüsse in das System angezeigt, sondern auch Nachrichten, die zum zweiten Mal in die Warteschlange zurückkehren und vielleicht sogar noch ein drittes oder viertes Mal. Diese Belastung kann im Laufe der Zeit drastisch ansteigen und sich sowohl auf die Kosten als auch auf das Serviceniveau auswirken.
Um dies zu verhindern, haben wir einen Mechanismus implementiert, bei dem Dienste, die ein Flag setzen, das anzeigt, dass sie noch Nachrichten verarbeiten, "ausgesperrt" werden. Dadurch wird verhindert, dass solche Instanzen Skalierungsentscheidungen unterworfen werden. Die meisten Cloud-Anbieter bieten Funktionen an, mit denen Instanzen selektiv "geschützt" werden können. Sobald der Dienst die Nachrichtenverarbeitung abgeschlossen hat, nimmt er die Markierung zurück und kehrt in den Pool der am Skalierungsspiel teilnehmenden Rechenressourcen zurück. Diese Funktion stellt sicher, dass nur untätige Maschinen in die Skalierung einbezogen werden.
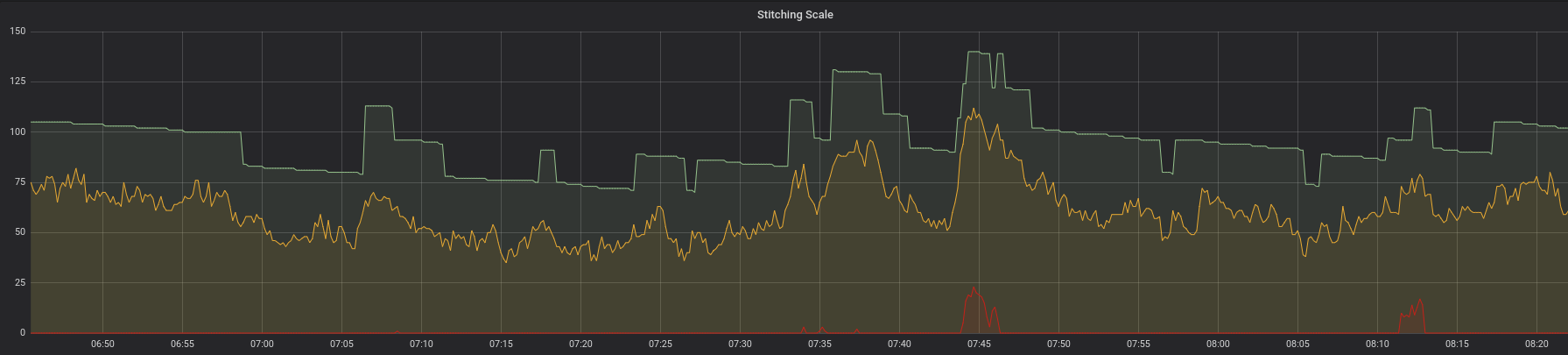
In der obigen Grafik sehen wir, dass Angebot und Nachfrage im Einklang stehen. Aber beachten Sie etwas, das wir vorher nicht gesehen haben. Es gibt eine neue rote Linie, die immer in der Nähe der X-Achse bleibt. Diese Linie stellt die Verzögerung in unserem System dar. Dies ist die Zeit, die die älteste Nachricht in der Warteschlange verweilt, bevor sie verarbeitet wird. Die Tatsache, dass die Angebots-Nachfrage-Linien so funktionieren, wie sie sollten, und dass die Verzögerung zu den meisten Zeiten nahe bei Null liegt, bedeutet, dass das Serviceniveau nicht beeinträchtigt ist.
Robustes Fallback
Wie Werner Vogels, CTO von Amazon, sagt: "Alles schlägt ständig fehl". Wir haben eine wichtige technologische Änderung eingeführt und einen Dienst entwickelt, der die Warteschlangentiefe und die in Bearbeitung befindlichen Nachrichten misst und einen Skalierungsvorgang für unser System durchführt. Wenn dieser Dienst ausfällt, bedeutet das, dass wir alle Skalierungsmöglichkeiten verlieren - der Stoff, aus dem die Albträume der CTOs gemacht sind. Um dies zu verhindern, wird ein Notfallplan erstellt. Der ursprüngliche Mechanismus der Abfrage der Warteschlangentiefe alle 5 Minuten ist nach wie vor in Kraft, und die beiden Systeme arbeiten parallel. Wenn eines der beiden Systeme ausfällt, hat das keine großen Auswirkungen auf die Servicequalität.
Die Schlussfolgerungen
Hier sehen Sie eine Darstellung unserer voll funktionsfähigen Lösung an einem typischen Tag in der Wochenmitte:
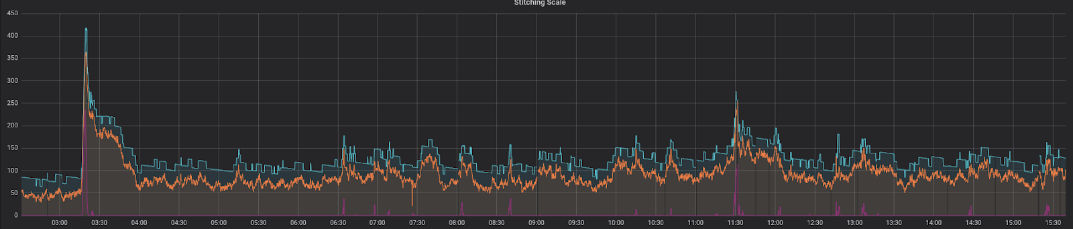
Dies zeigt eine perfekte Korrelation zwischen den erwarteten (orangefarbene Linie) und den tatsächlichen Maschinen (blaue Linie), mit ausreichender Reserve an Rechenleistung. Die Zeitspanne, in der die älteste Nachricht in der Warteschlange verbleibt, bevor sie verarbeitet wird (rote Linie), ist konstant niedrig und weist nur in sehr kurzen Zeiträumen Spitzen auf.
Zusammenfassend lässt sich sagen, dass der Aufbau eines Skalierungsmechanismus für asynchrone ereignisgesteuerte Systeme, die Trax, auf vier Grundpfeilern beruht:
- Identifizieren Sie die richtige Bedarfskennzahl: Verwenden Sie die richtige Metrik sowohl für die Überwachung der Last als auch für die Durchführung von Skalierungsentscheidungen
- Häufige Probenahme: Sehr häufig messen und Maßnahmen ergreifen
- Skalierungssperre: Auslastung von Systemen aus dem Skalierungsspiel nehmen
- Robustes Fallback: Vermeiden Sie einen einzigen Ausfallpunkt und haben Sie immer einen Notfallplan in petto
Der Erfolg wird dadurch definiert, wie zufrieden die Vollzugsbeamten für das Spiel "Need for Scale" - der CFO, COO und CTO - mit der Lösung sind. Das Ergebnis dieser Innovation kommt allen zugute:
- (Kosten) Monatliche Einsparung von ca. 10.000 $ bei den Rechenkosten - bei Verwendung genau der Anzahl von Servern, die wir benötigen
- (SLA) Verbesserung der SLA durch Verkürzung der Wartezeit in Warteschlangen
- (Einfachheit) Vereinheitlichung von Warteschlangen mit hoher und niedriger Priorität zu einer einzigen Warteschlange
Eine Sitzung zu diesem Thema wurde auch von Michael Feinstein auf der Reversim 2018 gehalten. Klicken Sie auf die Schaltfläche "Play", um die vollständige Sitzung anzusehen.









