
מכיוון שמיקרו-שירותים ממקור אירועים הופכים לאחת הארכיטקטורות הפופולריות ביותר לבניית מערכות מבוזרות, עקביות לנתונים, בקנה מידה גדול, חברות רבות מוצאות את עצמן מתמודדות עם המשוואה האולטימטיבית של יעילות מערכת לעומת עלות. להיות מוכן להזרמת נתונים בקנה מידה גדול בכל זמן נתון תוך שמירה על עלות המחשוב הנמוכה ביותר הוא אתגר שעמדנו בפנינו גם ב-Trax. בבלוג זה נציג את הפתרון הייעודי שלנו באמצעות כמה ממשקי ה-API הבסיסיים שניתנו על ידי כל ספקי הענן. גישה חדשנית זו סייעה לנו למזער את העיכובים במערכת ולחסוך ~65% מעלות המחשוב.
החדשנות המתקדמת הזו הוצגה על ידי AWS בפרק של This is My Architecture.
ב-Trax, אנו עושים דיגיטציה של העולם הפיזי של הקמעונאות באמצעות Computer Vision. הפיכת תמונות מדף בודדות לנתונים ותובנות לגבי תנאי החנות הקמעונאית מתאפשרת באמצעות 'מפעל טראקס'. נבנה באמצעות ארכיטקטורה מונעת אירועים אסינכרוני, Trax Factory הוא אשכול של מיקרו-שירותים שבהם השלמת שירות אחד מפעילה את ההפעלה של שירות אחר.
אדריכלות המפעל של Trax Computer Vision
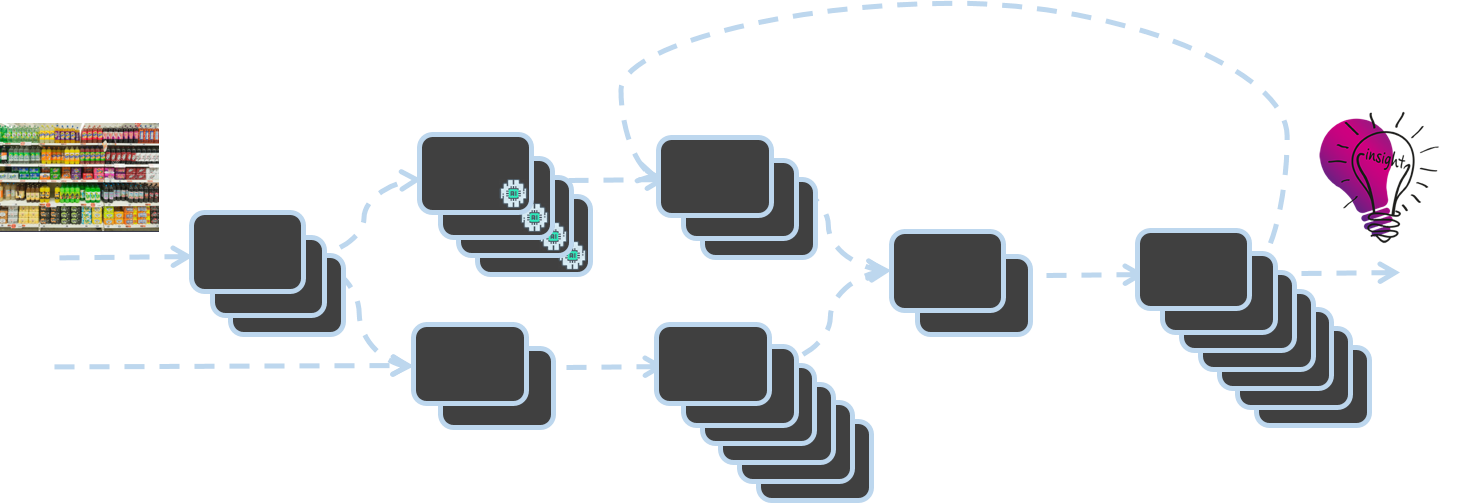
בלוג זה דן בצורך בתשתית חזקה וניתנת להרחבה לתמיכה במפעל Trax ומציג פתרונות חדשניים שפותחו על ידי מהנדסי Trax להוספה והסרה של קיבולת בהתאם לביקוש. למד כיצד Trax בנה מערכת מבוססת EC2 Auto Scaling Groups לעיבוד הודעות עבור SNS/SQS שיכולה לשנות קנה מידה כל שנייה. הפתרון שלנו חורג מסריקת עומק תורים קלאסית של 5 דקות עם CloudWatch, ומאפשר לנו להפחית את זמן ההשבתה, למנוע אובדן נתונים ולשפר את רמות השירות הכוללות.
הצורך בקנה מידה
בתחילת שנות ה-90, Electronic Arts פרסמה משחק וידאו מירוצים בשם Need for Speed שהטיל על שחקנים להשלים סוגים שונים של מירוצים תוך התחמקות מאכיפת החוק במרדף משטרתי.
זה היה גם בערך באותו זמן שבו מחשבים ששימשו חברות שונות הפכו מפוזרים יותר, ומדענים וטכנולוגים חקרו דרכים להנגיש כוח מחשוב בקנה מידה גדול ליותר משתמשים באמצעות שיתוף זמן. כך החל עידן מחשוב הענן, ואיתו האתגר המתמשך של אופטימיזציה של תשתיות. במשחק הזה של Need for Scale, צוותי תשתית מוסיפים ומסירים קיבולת מערכת תוך עמידה בחוקים שהופעלו על ידי מנהלי ניהול, מנהלי כספים ו-CTO. מהנדסי Trax, כמו עמיתיהם בחברות טכנולוגיה אחרות מבוססות ענן, היו צריכים לייעל את קנה המידה תוך שיפור רמות השירות ללקוחות, הפחתת עלויות ושמירה על פשטות מערכת ה-IT.
אתגר קנה המידה ב-Trax
ל-Trax יש את פלטפורמת Computer Vision המתקדמת ביותר לקמעונאות בתעשייה, עם מערכת backend מתוחכמת המעבדת מיליוני תמונות מדף בכל חודש.
תמונה חדשה שנכנסת למערכת היא אחד האירועים העיקריים המטופלים על ידי ה-Trax backend. אירוע זה מפעיל שירות מיקרו המזהה מוצרים בתמונה באמצעות אלגוריתמים מתקדמים של למידה עמוקה. תהליך זה הוא אסינכרוני בכך שאין שירות מיקרו אחר שמחכה לתגובה משירות זיהוי תמונות זה. המשימה שלו מסתיימת כאשר הוא מפרסם אירוע לאחר שהוא משלים את פעילות העיבוד ומספק את התוצאות. שירותי מיקרו שונים במפעל Trax פועלים בצורה זו, ומבצעים ללא הרף פעילויות רבות כמו תפירה, גיאומטריה ועוד, כל אחת מהן כרוכה בדרגות שונות של מורכבות חישובית.
הפיכת מיליוני תמונות על פני פרויקטים מרובים ברחבי העולם לתובנות ממוקדות וספציפיות עבור לקוחות גוזלת כוח סוס מחשוב רב תוך עומס על תקציבי IT.
בדרך כלל, החלטות אם להרחיב או להגדיל את הקיבולת (הוספה או הקטנה של מכונות בהתאמה) מתקבלות על סמך מדדי עומק תור בסיסיים שמסופקים על ידי ספקי ענן - למשל כמה הודעות יש בתור.
ישנם שני חסמים משמעותיים עבור מדיניות קנה מידה זו:
- זמן החימום של מכונה חדשה הוא ~3 דקות
- ספקי ענן מדווחים על מספר ההודעות בתור אחת ל-5 דקות
במערכת מורכבת כמו Trax שבה תמונות נכנסות למפעל בנפחים משתנים, והעומס על כל שירות שונה מהאחר, מידע על עומק התורים הופך מיושן במרווחים של 5 דקות. זה מציג את הסיכון של לא רק לזהות את כוח המחשוב הנדרש באיחור רב ולפגיעה ב-SLAs, אלא גם לגרור עלויות נוספות תוך ביצוע התאמות בקנה מידה.
איור של מוניטור קנה מידה באמצעות מדדי קיבולת מחוץ לקופסה
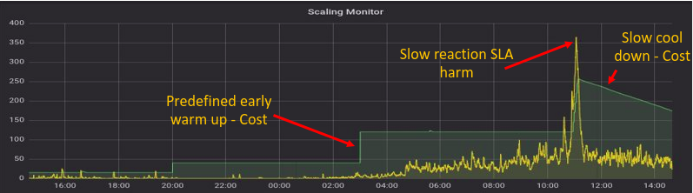
- גרף צהוב מציין את המספר הצפוי של המחשבים הדרושים בהתחשב בסה"כ ההודעות בתור והודעות בתהליך
- גרף ירוק הוא המספר האמיתי של מכונות בפלטפורמת ענן
כפי שמראה התרשים, הסתמכות על מדדים מחוץ לקופסה לניטור ניצול הקיבולת כל 5 דקות מביאה לעלויות על מכונות שאינן בשימוש, כמו גם פגיעה ברמות השירות על ידי הפעלת מכונות לא מתאימות (למשל בין 10.00 ל-12.00 בתרשים).
מעבר לעומק התור כמדד קנה מידה
עומק התורים היה וימשיך להיות גורם משפיע מרכזי בהגדלת החלטות במערכות מבוססות אירועים. אבל הסתמכות רק על עומק התורים כמדד קנה מידה יוצרת גישה תגובתית לאופטימיזציה של תשתית.
כשיש הודעה ממתינה בתור, זה לוקח זמן חישוב יקר שאנחנו מעדיפים לבזבז על הודעה שנמצאת בעיבוד על ידי שירות. לכן, זה אידיאלי להחזיק כמות מסוימת של כוח מחשוב פנוי בכל זמן נתון. מערכות חילוף אלו ממתינות להודעות חדשות שיגיעו לתור כך שניתן יהיה לעבד אותן באופן מיידי ללא עיכובים. באופן טבעי, גישה פרואקטיבית זו עדיפה על הצורך להוסיף מכונות כאשר ההודעות כבר נמצאות בתור ולהתקדם כאשר התור כבר ריק. הצורך בכוח חילוף חושף תובנה חשובה – עומק התורים לא מספר את כל הסיפור.
אז, המשוואה הנכונה לשינוי קנה מידה צריכה להיות למעשה:
דרישה = הודעות בתור + הודעות בתהליך + מכונות רזרביות
המארז למדידת קיבולת ועומס תכופים יותר
כפי שקבענו בסעיפים הקודמים, הסתמכות על מדדי קנה מידה רק פעם ב-5 דקות היא לא רק יקרה אלא גם פוגעת ברמות השירות ושביעות רצון הלקוחות. כדי להתגבר על זה, פיתחנו שירות שמודד את עומק התורים והודעות בתהליך כל שנייה באמצעות API. בהשוואה בין שיטת הדגימה הישנה לחדשה, השיפורים היו ברורים מאוד. באיור למטה, הביקוש (קו צהוב) לעולם אינו עולה על ההיצע (קו ירוק).
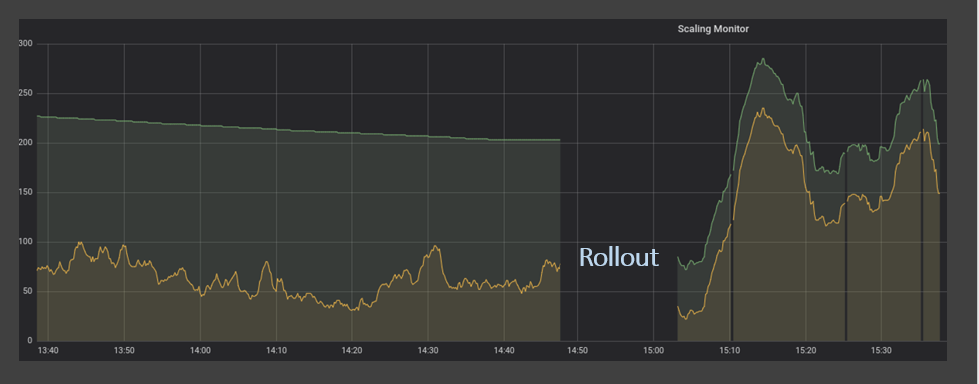
שימו לב שכאשר הביקוש עולה בחדות, ההיצע מגיב מהר מאוד ומגן ביעילות על הלקוחות שלנו מפני עיכובים לא נעימים בשירות.
בנוסף, שיטה זו עוזרת לשמור על כוח המחשב הספציפי שלנו בהתאמה הדוקה לביקוש במקום לבזבז אותו על מקרים סרק שממתינים להודעות חדשות.
קנה מידה פנימה והחוצה בזהירות
לשינוי קנה מידה אגרסיבי שנעשה בצורה שגויה יש סכנה אחת ברורה ונוכחת - אפשרות לשינוי קנה מידה במכונות שעדיין מעבדות מידע. במפעל Trax, למשל, אלגוריתמים מבוססי גיאומטריה תופסים יותר זמן עיבוד בהשוואה לשירותים אחרים. הוצאת כוח מחשוב משירות זה מוקדם מדי מביאה להחזרת ההודעה לתור. כתוצאה מכך, בנוסף לציון הזרמה הטבעית למערכת, דוחות הביקוש כוללים הודעות שחוזרות לתור בפעם השנייה, ואולי חוזרות בפעם השלישית או הרביעית. עומס זה יכול לגדול באופן דרסטי לאורך זמן ולהשפיע הן על העלויות והן על רמות השירות.
כדי למנוע זאת, הטמענו מנגנון שבו שירותים שמרימים דגל המציין שהם עדיין מעבדים הודעות 'נעולים'. זה מונע מקרים כאלה להיות נתונים להחלטות קנה מידה. רוב ספקי הענן מציעים תכונות ש'מגנות' על מופעים באופן סלקטיבי. לאחר שהשירות משלים את עיבוד ההודעות, הוא מוריד את הדגל וחוזר למאגר משאבי המחשוב המשתתפים במשחק קנה המידה. יכולת זו מבטיחה שרק מכונות סרק יוגדלו.
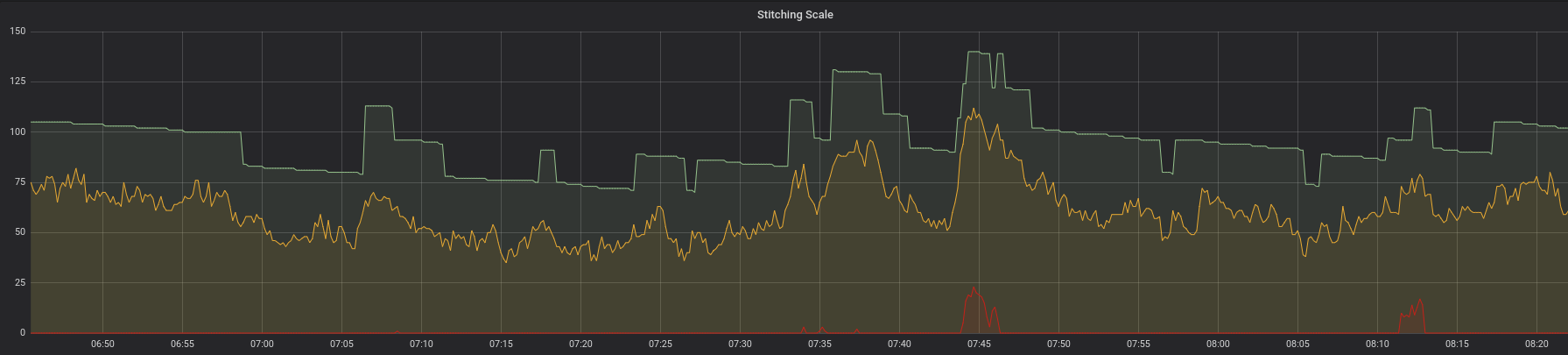
בגרף למעלה, אנו רואים ביקוש והיצע בהרמוניה. אבל שימו לב למשהו שלא ראינו קודם. יש קו אדום חדש שתמיד נשאר קרוב לציר ה-X. קו זה מייצג את ההשהיה במערכת שלנו. למעשה, זהו משך הזמן שבו ההודעה הישנה ביותר נמצאת בתור לפני העיבוד. העובדה שקווי ביקוש היצע מתפקדים כפי שהם צריכים בשילוב עם העיכוב קרוב לאפס ברוב הפעמים פירושו שרמות השירות לא נפגעות.
חזרה חזקה
כפי שאמר ורנר ווגלס, CTO של אמזון, "הכל נכשל כל הזמן". הכנסנו שינוי טכנולוגי גדול ופיתחנו שירות שמודד את עומק התורים והודעות בתהליך ומבצע פעולת קנה מידה במערכת שלנו. כישלון שירות זה פירושו למעשה שנאבד את כל יכולת ההרחבה - החומר שממנו מורכבים הסיוטים של CTO. כדי למנוע זאת, מופעלת תוכנית התאוששות מאסון. המנגנון המקורי של שאילתת עומק התורים כל 5 דקות עדיין קיים ושתי המערכות פועלות במקביל. בדרך זו, אם אחד מהם קורס, רמות השירות לא מושפעות מאוד.
הטייק אווי
הנה תיאור של הפתרון הפונקציונלי המלא שלנו שעובד ביום טיפוסי באמצע השבוע:
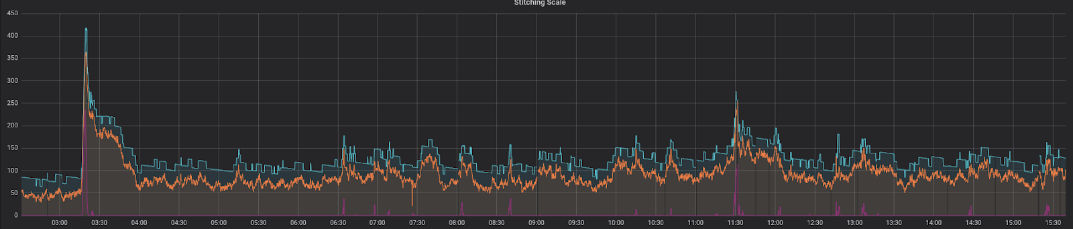
זה מראה מתאם מושלם בין המכונות הצפוי (הקו הכתום) למכונות בפועל (הקו הכחול), עם כמות מספקת של כוח חישוב רזרבי. משך הזמן שבו ההודעה הישנה ביותר נמצאת בתור לפני עיבודה (קו אדום) נמוך באופן עקבי, ועולה רק לפרקי זמן קצרים מאוד.
לסיכום, בניית מנגנון קנה מידה עבור מערכות מונעות אירועים אסינכרוניים שלטראקס יש ארבעה עמודי יסוד:
- זהה את מדד הביקוש הנכון : השתמש במדד הנכון הן של ניטור עומס והן של ביצוע החלטות קנה מידה
- דגימה תכופה: מדוד ובצע פעולות בתדירות גבוהה
- נעילת קנה מידה: הוצא מערכות תפוסות ממשחק קנה המידה
- סתירה חזקה: הימנע מנקודת כשל בודדת ותמיד קיים תוכנית התאוששות מאסון
הצלחה מוגדרת על ידי מידת האושר של קציני אכיפת החוק למשחק Need for Scale - סמנכ"ל הכספים, ה-COO וה-CTO - מהפתרון. התוצאה של חדשנות זו מועילה לכולם:
- (עלות) חיסכון של ~$10K מדי חודש על עלות מחשוב - תוך שימוש בדיוק במספר השרתים שאנו צריכים
- (SLA) שיפור SLA, על ידי צמצום זמן ההמתנה בתורים
- (פשטות) איחוד של תור בעדיפות גבוהה/נמוכה, לתור בודד
מפגש בנושא זה הועבר גם על ידי מיכאל פיינשטיין ברורסים 2018. לחץ על כפתור ההפעלה כדי לצפות בסשן המלא.









